Abstractions
Basic concepts of computer systems.
Disclamer: All the learning notes here are from Advanced Computer System, delieved by UCPH.
Why study (big) computer systems?
“How can I program large systems with clean interfaces and high performance? “
“How do I build systems to process TBs to PBs of data?”
1TB = 1000GB, 1PB = 1000TB
“How can I understand the guarantees and reliability of scalable services offered to me on the cloud?”
How to ensure I am accessing my data, instead of others?
What is the scale of our computer systems?
According to the data in 2007, there is an increasing number of users and mountainous data for us to process. Building a system capable of processing such data is extremely demanding right now. To conclude with a specific example. How to build a trust-worthy “Facebook”?
What should we learn in this course?
Knowledge
Describe the design of transactional and distributed systems, including techniques for modularity, performance, and fault tolerance.
Explain how to employ strong modularity through a client-service abstraction as a paradigm to structure computer systems, while hiding the complexity of implementation from clients.
- By implementing this, strong modularity will prevent the entire system down when a failure happens in a module or a component. How to achieve this principle by using client-service abstraction. Hide the complexity from the abstraction.
Explain techniques for large-scale data processing.
Skills
Implement systems that include _mechanisms for modularity, atomicity, and fault tolerance_.
Structure and conduct experiments to evaluate a system’s performance.
Competences
Discuss design alternatives for a modular computer system, identifying desired system properties as well as describing mechanisms for improving performance while arguing for their correctness.
Analyze protocols for concurrency control and recovery, as well as for distribution and replication.
Apply principles of large-scale data processing to analyze concrete information-processing problems. (Realize and build a model for addressing the future problem.)
What will we study?
Topic 1: Strong Modularity
- Fundamentals that build a system from the fundamentals. The property is Strong Modularity.
- Abstractions: interpreters, memory, communication links. => Any large-scale systems that are built starting from the 3 fundamentals. They interacted with each other.
- Modularity with clients and services, RPC => Remote procedure calls
- Techniques for performance, e.g., concurrency, fast paths, dallying, batching, speculation
Strong modularity means building systems from components where the value of one component does not influence the rest of the system or does not severely influence the rest of the system maybe. Which has been mentioned above.
Topic 2 Atomicity, Isolation, and Durability
-
Concurrency control and recovery
One way to implement memory abstraction as is done is in large-scale database management systems. And they are about to achieve certain properties for this memory abstraction mainly atomicity isolation and durability. And the techniques to achieve them are concurrency control and recovery.
Properties: Atomicity, Isolation, and Durability.
-
Experimental design (Not the key points in this course)
- Performance metrics, workloads
- Structuring and conducting simple experiments
Topic 3 High Availability
-
Reliability & Distribution
Reliability means how we make sure if our system is built from a lot of components and the components I expected to fail. What are the best strategies to ensure that the system overall is available and achieves its goals?
-
Communication
-
Property: High Availability => we want our systems to be online all the time and the service should not be interrupted by a failure of small components.
Topic 4 Scalability with Data Size
-
Data processing
More about algorithms and how to improve the performance with algorithms that implement parallelism.
-
Property: Scalability with Data Size
What should we learn today?
-
Identify the fundamental abstractions in computer systems and their APIs, including memory, interpreters, and communication links.
Fundamental abstractions allow us to break down a complex computer system into smaller pieces with a reasonable API that we can understand what it does no matter how complex the implementation of that API is.
Specifically, we look at memory, interpreters, and communication links.
-
Explain how names are used in the fundamental abstractions
How these three fundamental abstractions work and communicate with names (APIs).
-
Design a top-level abstraction, respecting its correspondent API, based on lower-level abstractions
-
Discuss performance and fault-tolerance aspects of such a design.
The central Tradeoff
When implementing a computer system, abstractions and performance and fault-tolerance are limited by each other. On the one hand, we would like to keep the clean interfaces so we need to have as simple components (abstractions). On the other hand, we still need to get the most use of performance which means we need to break the abstractions. Hence, we need to find ways where abstractions are sensible barriers that do not end up performance. Then, the final part is fault-tolerance.
When introducing an abstraction, we will have a barrier between two components, and in particular, you will need to have a communication mechanism on this barrier. Hence, when introducing components, we increase the attack. (Not fully understood)
Fundamental abstractions
Memory abstraction (Read/Write)
A memory abstraction is something that allows you to read values and write values.
Interpreters abstraction (loop(print(eval(read))))
Have a set of commands that you can execute and the interpreter’s input instructions from somewhere else. They evaluate the instructions and print some output and continue this in a loop.
Communication links abstraction Send/Receive
It can be async and we don’t wait for the response or something like that.
Names make connections (glue) between these abstractions. Where do we read from or where do we write to? It can be any kind of format, e.g., addresses, IP addresses, web addresses, filenames, emails, telephone numbers, and so on.
Sometimes, we call a name an address if it has some location information. Address is an overloaded name with location info. (e.g., LOAD 1742, R1). The rest of the names require a mapping scheme to translate the original info into a fixed location. For example, a website is commonly associated with an IP address, and so on.
Name Mapping
How can we map names?
We usually have some algorithms that take as input the names and some contexts and produce the addresses.
Type 1: Table lookup Files inside directories.
Typically, there will be something like a table lookup first so you could look up a file inside of a directory by taking the file name depending on the file system you are using, the precise lookup may look differently, but in practice, it translates to a table lookup or you can contact the DNS service to resolve the web address to an IP address. All these are called table lookups.
Type 2: Recursive lookup Path names in file systems or URLs
There might be some names structured with /, just like URLs, web addresses, or file paths. We need the recursive lookup or combine it with the table lookup to get to the location we are interested in.
Type 3: Multiple lookup Java class loading
When we code Overloading with Java, we might call a method in Java. This can be long multiple classes and you try to find or Java tries to find the best matching instance of the class to pick the implementation of the method you’re interested in. It is based on the types of objects involved.
Memory Abstraction
API of the memory
READ(name) -> value: read from a name and obtain a value
WRITE(name, value): where to write and which value to write
Examples of Memory
Physical memory is limited to the size of the RAM chip, virtual memory is limited by the size of the hard disk.
RAM stores virtual addresses, while the disk stores physical addresses.
Typically, when we are writing to the physical memory and our computer, we are using a physical address but typically we don’t address the RAM directly. But we work with a multi-level memory hierarchy that goes from memory that we can access quickly like the RAM.
How would you design a two-level memory abstraction consolidating disk and RAM?

RAM is extremely expensive and it is volatile, but its speed is fast. While the Disk is in contrast that the price is very low and it is nonvolatile, however, it is high latency. Design top-level abstraction respecting Memory API.
Requirements below
- Address as much data as fits in disk
- Use fixed-size pages for disk transfers
- Use RAM efficiently to provide for low latency (on average)
- Neither disk nor memory directly exposed, only
READ/WRITEAPI.
What does it mean to implement an abstraction? - What we need to do is implement the read and write functions and hide the two-level hierarcy to the users.
Proposal by the student
Store both data in the RAM and disk. And always access the RAM first, if RAM finds the value, that’s good. When does not, then RAM would swap in the data from disk and to swap in RAM would use. Maybe at least recently use strategy to decide which page from the disk answer from the RAM to swap out.
This is principal right, but an advanced version with smart data structures is below.
Hint
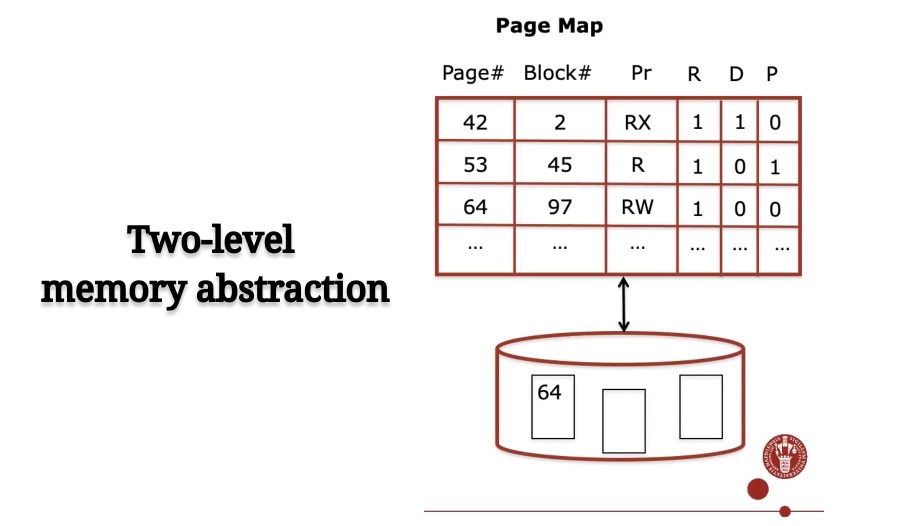
We have two address spaces, we have the addresses on the disk and addresses on the RAM. We need to bridge the gap between the two. So we introduce the naming scheme that operates with addresses of disk + RAM. So those are the virtual addresses and they give us as many addresses as we can access with the extraction. And we need to have something that translates these virtual addresses into concrete physical addresses. This could be a disk address or memory address. So the page map for example will have the virtual address, the page identifier and that will translate to the block number. Maybe on the disk first time I saw the block number memory. Let’s start with that.
RAM stores most recently used pages and page map. Resident bit (R): access to non-resident pages results in page faults. Page fault:an indirection exception for missing pages.

Trap to OS handler and handler loads block from disk and updates mapping. If memory full, must choose some victim block for replacement. Page replacement algorithm, e.g., LRU.
Other metadata: Dirty bit (D): Only write page back when it has changed! Pin bit (p): do not remove certain pages (e.g., code of OS handler itself)
Answer
To achieve this objective, we should put a page map recording #Page, #Block, Pr, R, D and P into the RAM, with some pages selected automatically which are mostly used recently by the computer. Then, when accessing a data. The computer system will access the RAM to lookup the table. Check whether the page is resident or not by verifing its resident bit. If value is 1, then just get the data from the table which is already stored in the RAM. If not, check whether the RAM is full or not. If it is already full, apply LRU strategy to find out the record which is ready to replace. Then, check its dirty bit whether it is 1 or 0. If the value is 1, write the page back to the disk, then, clear that page in the RAM and replace it with the needed new page. Otherwise, clear and replace the needed new page.s
Virtual Memory with Paging
Abstraction: Do we have any guarantees on two concurrent threads writing to the same memory?
- No, we don’t have any guarantees regarding concurrent access.
Performance: Do we get average latency close to RAM latency?
- Yes. LRU strategy should give us the average latency that is close to RAM.
Fault-Tolerance: What happens on failure? Do we have any guarantees about the state that is on the disk?
- Depends on the data. If the fault happens in the disk, there might be only one page lost. However, if the electricity is running out, all the data stored in the RAM will lose.
Interpreters Abstraction
Examples of interpreters
Communication links
API: SEND(linkName, ourgoingMessageBuffer), RECEIVE(linkName, incomingMessageBuffer)
Examples of Communication Links
Other useful abstractions
Sychornization, data processing